When the main app is clean, go count the URL fetchers
There’s a trap in testing a polished product. You hammer the core flows, the auth is tight, the obvious injection points are all handled, and you quietly conclude the whole target is hard. So you move on. That’s the mistake. The team poured its attention into the thing users see every day. The soft tissue is in the features off to the side, the ones a different person shipped on a different Tuesday while thinking about something other than your collaborator server.
The shift that pays here is where you look. Not at the main app everyone hardened. At the small, boring features bolted onto the edges, sharing the same production backend, written by people who were thinking about a feature and not about an attacker pointing it inward.
The thing that fetches URLs for you
Pick any product bigger than one screen and list every place the backend goes and fetches a URL on your behalf. Once you start counting they’re everywhere:
- avatar-by-URL (“set your picture from a link”)
- import-from-URL on basically any object
- link preview / unfurl in comments and chat
- webhook “send test event” buttons
- PDF or screenshot generation from a URL
- OAuth and SAML metadata fetchers
Each one is its own SSRF candidate, because each one is a different code path with a different author. The discipline that locked down the main app does not automatically reach whoever wired up link previews. So you don’t test “the product.” You test each fetcher, separately, like they’re six different targets that happen to share a logo.
Import-from-URL is a good one to start on. You hand it a link, the server fetches it to check there’s something valid on the other end, and that fetch is the whole game.
Two walls, and what they actually tell you
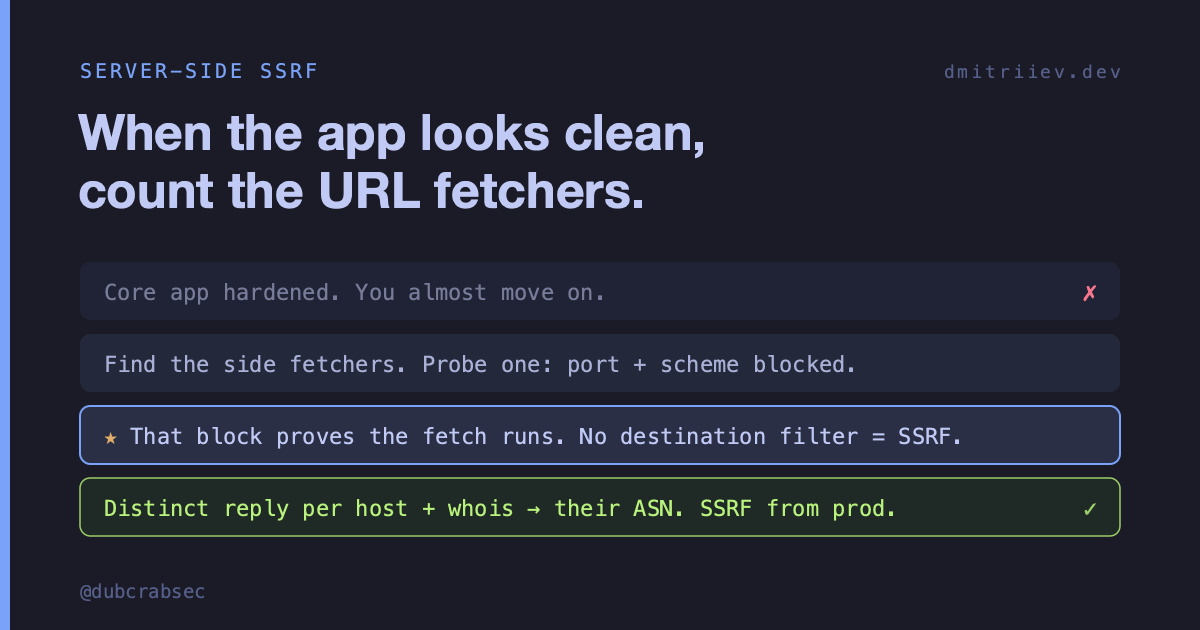
First thing you notice: it’s usually not wide open. Hand the fetcher a non-HTTP scheme and you get a clean rejection. Point it at a weird port and it tells you the port isn’t allowed; the allowlist is basically 80 and 443. Most people read that as “they thought about SSRF, move on.”
Read it the other way. Those partial controls are a confession that the fetch path is reached and running. A port allowlist can only fire after something decided to connect. The scheme check can only reject file:// if it parsed your input as a URL it intended to fetch. The defenses prove the door opens. They just forgot to check who’s on the other side: there’s often no filter on the destination address. Allowed port, internal host, and it goes.
Partial mitigation is not a wall. It’s a sign saying “the interesting code lives right here.”
The oracle: a different answer per target
This is the part that turns “looks vulnerable” into a report a triager believes. The risk with any blind-ish SSRF is that the server returns some generic error and you talk yourself into believing it connected when it just bounced you at the edge. You need proof the backend genuinely reached out and is telling you the real outcome.
So you point the same endpoint at a handful of internal destinations and read the differences in what comes back. The pattern you’re hoping to see looks like this:
- an internal host that’s up but refuses you relays its real upstream status (say a
403) straight through - a dead address comes back as a generic “couldn’t fetch”
- a blocked port comes back as something like “port not allowed”
Different destinations, distinct reasons, all from one endpoint. A canned block can’t do that. If the server were faking it, every internal address would return the same string. Distinct outcomes per target mean it’s actually connecting and reporting what it found, which is exactly the primitive you wanted: an internal scanner and a service fingerprint, status code included.
Prove it left the building
One more step, and skipping it is why a lot of SSRF reports read as weak. Reaching internal addresses from your own session is suggestive. It is not proof the fetch came from their network rather than a sandbox, a proxy pool, or your own machine doing something dumb.
Point the fetcher at an out-of-band collaborator you control and watch the inbound request land. Then whois the source IP. When that address maps back to the target’s own ASN, you’re done arguing: the fetch left their production network, full stop. Put that in the report and the triager doesn’t have to take your word for where the traffic came from. They can see it.
The argument that sets the severity
Here’s the move that makes it land instead of getting waved off as “intended behavior.” Look at the other fetchers in the same product and compare how they egress.
Often you’ll find some of them are already locked down. One path returns no status at all and clearly leaves from a segmented range; another never touches anything internal no matter what you feed it. Then there’s the one you’re reporting, sitting on the main backend and leaking status. That contrast is the whole argument: the same team already knows how to isolate a server-side fetcher, because they did it elsewhere. So the leaky one isn’t a deliberate design choice, it’s the fetcher that got missed. Consistency between a product’s own features is one of the most persuasive severity arguments you have, and almost nobody bothers to go check the neighbors.
What it is, and what it isn’t
Calibrate this honestly. An authenticated user can drive the backend to hit internal hosts on allowed ports and read each one’s reachability and HTTP status. That’s internal network mapping and service fingerprinting from the outside, which lands around Medium on most programs. It is not RCE and it is not a data dump. Confirm reach against a single private host and stop. The point is to prove the gap, not to go spelunking through someone’s internal network, and a triager trusts the report that obviously knew where to stop.
The bug isn’t really the lesson here. The lesson is where it lived. A team that ships a genuinely hard main product can still leave a server-side fetcher on the production network with no destination filter, because that fetcher was never the product, it was a feature off to the side. Next clean-looking target you’re about to write off, go count its URL fetchers first. The front door is the wall. The plumbing around it usually isn’t.